When I joined Noodle.ai (now DayBreak), the company was stuck. Engineers wanted time to build a solid platform. Consultants needed fast solutions for clients. Both sides had valid concerns, but the friction was slowing everything down.
I spent three months interviewing 50+ people across the company, from junior engineers to the CEO. The same problems kept surfacing: work sat in queues for weeks, handoffs failed between teams, and nobody could predict delivery timelines. We were burning people out with last-minute heroics instead of building systems that worked.
I picked up The DevOps Handbook by Gene Kim to find answers. The book gave me a framework to diagnose our problems and design solutions. After implementing these principles, we increased code reusability by 40% and cut six weeks off our production timelines. More significantly, we replaced ad-hoc heroics with scalable, repeatable processes.
Here’s what I implemented and the reasoning behind each decision.

The Three Ways: A Framework for System Thinking
The book structures DevOps practices around three core principles. I used these as evaluation criteria for every process change at Noodle.
Flow: Work should move smoothly from Development to Operations to the customer. You do this by making work visible, reducing batch sizes, and optimizing for company goals instead of team goals.
Feedback: Create fast feedback loops at every stage. When something breaks, you want to know immediately, not three weeks later when a customer reports it.
Continuous Learning: Build a culture where people can experiment and fail safely. You learn faster when people aren’t afraid to try new approaches.
I used them to evaluate every process change: Does this improve flow? Does it give us faster feedback? Does it help us learn?
Making Work Visible With Kanban
I implemented Kanban boards as the first intervention because you cannot optimize what you cannot measure, and you cannot measure what you cannot see. We represented every work item as a card and imposed strict work-in-progress (WIP) limits on each column.
The WIP limits were the critical mechanism. When a column reached capacity, we stopped accepting new work and focused resources on completing in-progress items. This appeared counterintuitive to engineers accustomed to maximizing individual utilization through multitasking.
The data proved otherwise. We discovered work items that had been idle for two weeks awaiting code review. We identified single-person bottlenecks blocking multiple parallel workstreams. Visibility transformed these from invisible problems into actionable issues.
The mathematics of queuing theory explains why this matters. At 50% resource utilization, average wait time equals one time unit. At 90% utilization, wait time increases to nine time units. In our case, work traversed seven functional teams before deployment. With each team operating at 90% utilization, total wait time reached 63 hours for 30 minutes of value-added work.
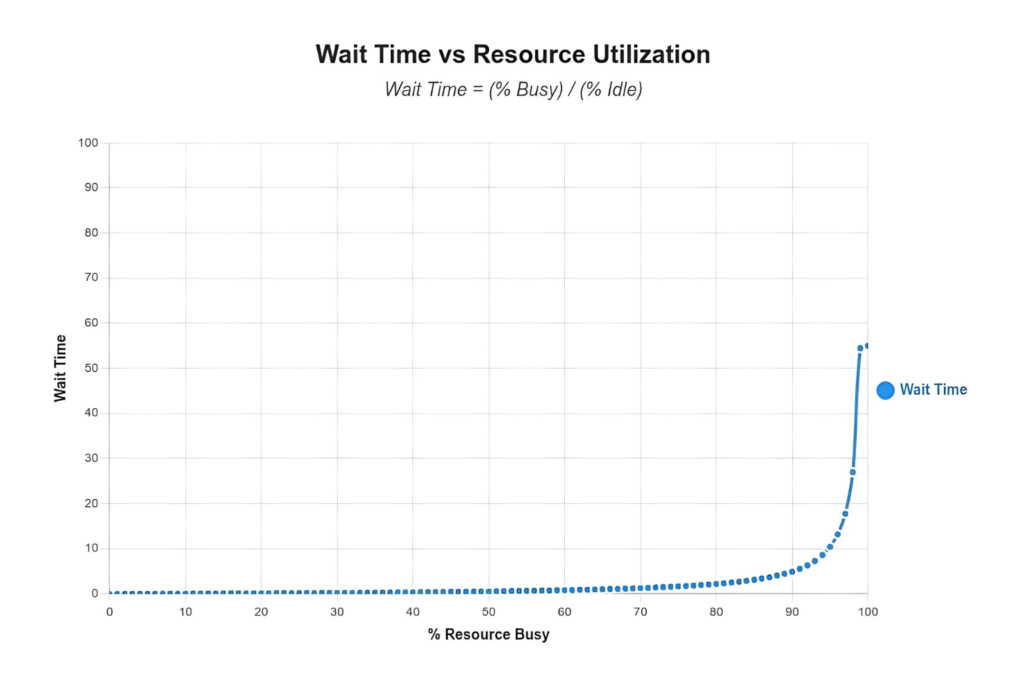 This is a structural problem. You cannot eliminate it through increased effort. The solution requires reducing WIP and addressing systemic constraints.
This is a structural problem. You cannot eliminate it through increased effort. The solution requires reducing WIP and addressing systemic constraints.
Reducing Batch Sizes: Why Small Changes Win
The book uses a simple example to explain batch sizes. You need to mail 10 letters. Each letter requires four steps: fold the paper, insert it in an envelope, seal the envelope, and stamp it.
Most people do this in batches. Fold all 10 papers, then insert all 10, then seal all 10, then stamp all 10. But if you discover on letter seven that you folded the paper wrong, you’ve already processed all 10. You have to start over.
With single-piece flow, you complete one entire letter before starting the next. You catch the mistake on the first letter and adjust immediately.
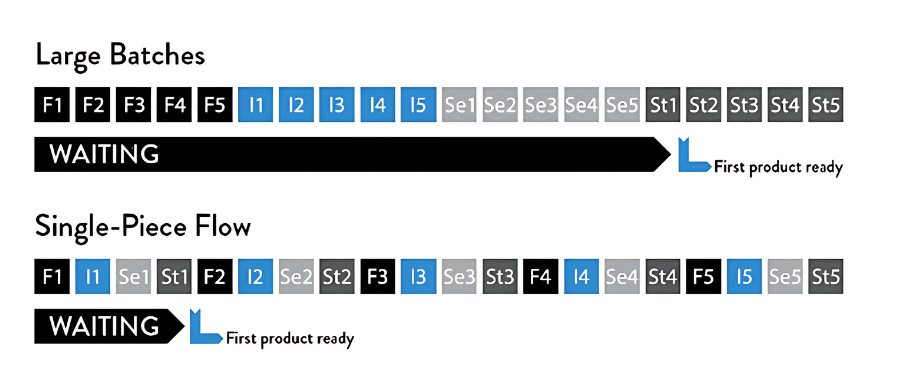 In software, single-piece flow means continuous deployment. Each code change gets tested and deployed to production independently. You find bugs in minutes.
In software, single-piece flow means continuous deployment. Each code change gets tested and deployed to production independently. You find bugs in minutes.
At Noodle, we decomposed large platform releases into independent, deployable modules. Engineers could ship a data pipeline enhancement without blocking on the quarterly release cycle. We developed reusable components: ML algorithms, documentation templates, and deployment automation. Each component could ship when it reached production readiness.
This required restructuring our planning process. Instead of three-month roadmaps containing 50 features, we focused on shipping one complete, tested feature at a time. The scope might be smaller, but the quality and deployability were non-negotiable.
The Andon Cord: Stopping Work to Fix Problems
Toyota production lines include a cord that any worker can pull to halt the entire line when they identify a problem. The entire team swarms the issue and resolves it before defects propagate downstream.
We implemented a virtual Andon cord for our build pipeline. When code broke automated tests, we stopped accepting new commits until the issue was resolved. No exceptions, no workarounds.
This policy initially generated pushback. Engineers expressed concern about development velocity. The outcome contradicted those concerns. When the entire team focuses on a single problem, resolution time drops from days to minutes. Additionally, developers increased their local testing rigor, not because of enforcement, but because they understood the systemic impact of broken builds.
The critical element was eliminating blame. We didn’t ask “who broke the build?” We asked “what information or constraints made this change appear safe, and how do we prevent similar issues systematically?”
Blameless Post-Mortems: Learning From Production Incidents
We conducted a structured post-mortem after every production incident. The format was standardized:
- Chronological timeline of events
- Decision rationale at each point (why actions seemed correct given available information)
- Systemic changes to prevent recurrence
- Ownership assignment for corrective actions
These documents went into a shared repository accessible company-wide. This wasn’t compliance documentation. It was knowledge transfer infrastructure.
A junior engineer unfamiliar with database failover scenarios could study how senior engineers handled one. A consultant could understand the technical complexity behind seemingly simple feature requests. Post-mortems became our institutional memory.
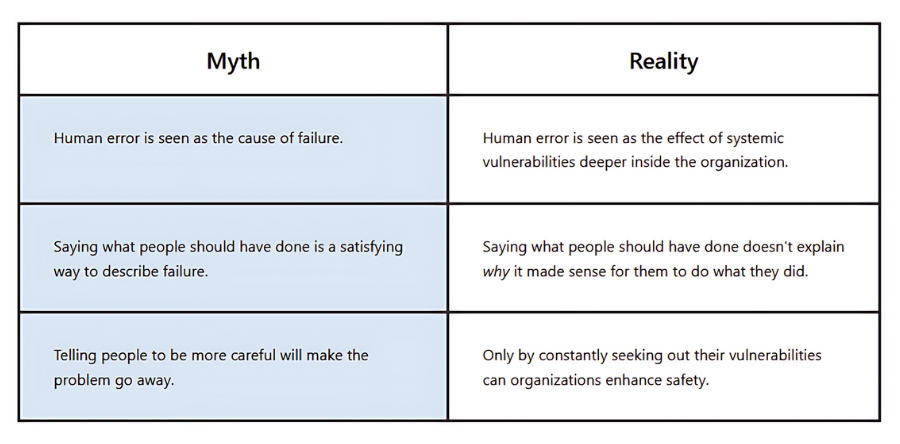
The blameless approach was essential. Questions about individual blame cause people to hide mistakes. Questions about decision rationale reveal the actual information gaps and constraints that led to problems. You learn from the second approach. You just create fear with the first.
Conway’s Law: Your Org Chart Becomes Your Architecture
Conway’s Law states that system architectures mirror the communication structures of the organizations that build them. At Noodle, our org chart was generating our bottlenecks.
We operated with functional teams: engineering in one group, consulting in another, data science in a third. Every project required coordination across all three teams. Engineers built features, handed them to consultants for deployment, who identified issues and returned them to engineering. Each handoff introduced multi-day delays.
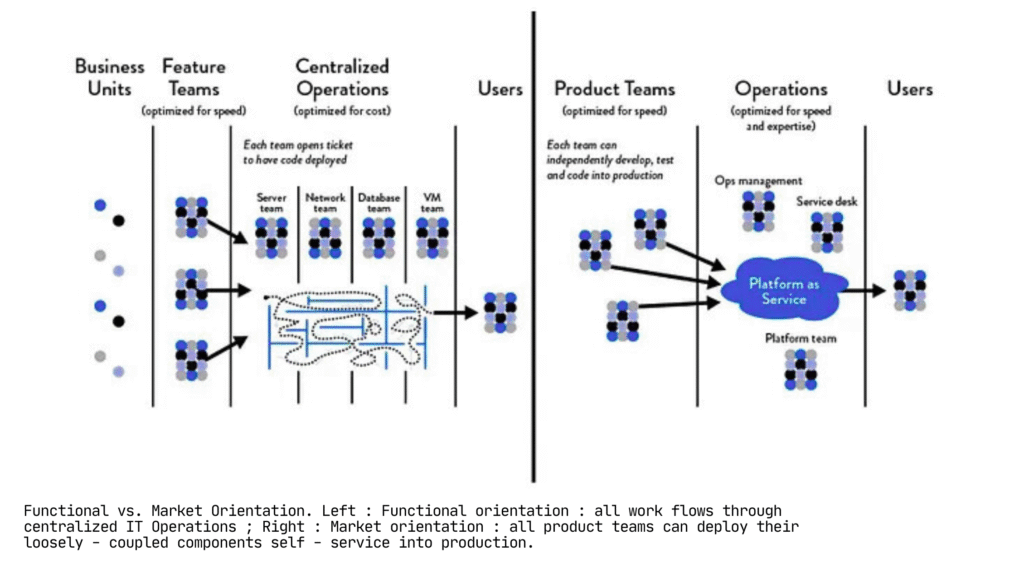
We reorganized around customer engagements rather than job functions. Each team included an engineer, consultant, and data scientist. They designed, built, tested, and deployed independently. No handoff tickets. No waiting for another team’s capacity.
This was the highest-impact organizational change we made. Small, cross-functional teams moved faster because they didn’t require external coordination to ship work.
Building a Deployment Pipeline
A deployment pipeline automates the path from code to production: commit to version control, execute automated tests, deploy to production-like staging, deploy to production.
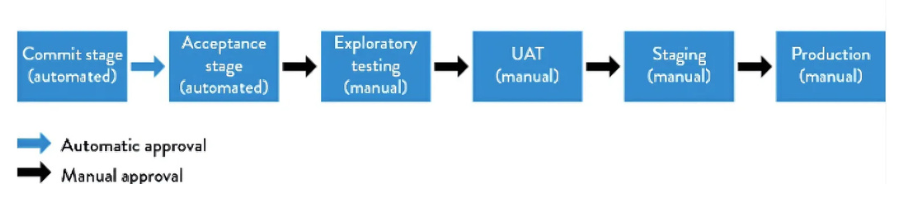 We established one non-negotiable rule: the main branch must be deployable at all times. No “fix it later” commits. No “don’t deploy on Friday” culture.
We established one non-negotiable rule: the main branch must be deployable at all times. No “fix it later” commits. No “don’t deploy on Friday” culture.
This required substantial investment in automated testing. We started with critical path tests and expanded coverage incrementally. Google enforces a hard requirement that no code merges without accompanying automated tests, because a single deployment error can affect their entire infrastructure. We adopted an identical standard.
 Tests executed automatically on every commit. Passing tests meant the code was production-ready. Test failures triggered immediate remediation before merge.
Tests executed automatically on every commit. Passing tests meant the code was production-ready. Test failures triggered immediate remediation before merge.
This approach forced smaller increments. You cannot commit half-finished features when the main branch must stay deployable. We used feature flags to deploy inactive code, or we decomposed features into independently shippable components.
 Trunk-Based Development: Why We Stopped Using Long-Lived Branches
Trunk-Based Development: Why We Stopped Using Long-Lived Branches
We used to work on feature branches for weeks before merging. This created massive merge conflicts and integration problems. By the time code was ready to merge, the main branch had moved so far ahead that integration took days.
We switched to trunk-based development. Everyone works on the main branch or on very short-lived branches that merge within a day. You commit small changes frequently instead of large changes rarely.
This felt risky initially. What if someone commits broken code? But the automated tests catch that immediately, and the Andon cord process ensures it gets fixed fast. The alternative is finding out two weeks later that three different branches have incompatible changes.
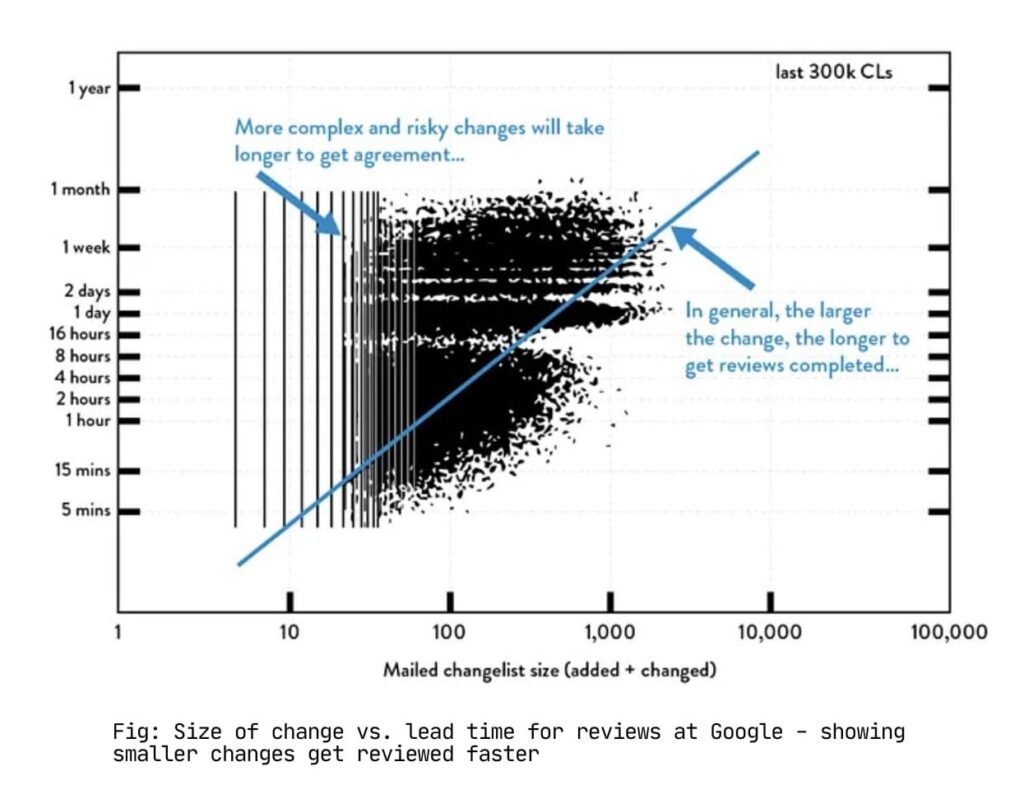 Google, Facebook, and other high-velocity companies use trunk-based development because it’s the only way to move fast with hundreds of developers.
Google, Facebook, and other high-velocity companies use trunk-based development because it’s the only way to move fast with hundreds of developers.
Keeping Teams Small: The Two Pizza Rule
Jeff Bezos has a rule: if you can’t feed a team with two pizzas, the team is too large. When teams grow beyond 8-10 people, communication overhead kills productivity.
We kept teams small and invested in cross-training. Engineers learned about the business problems we were solving. Consultants learned enough about the codebase to deploy simple changes themselves. Data scientists understood the production infrastructure.
This sounds inefficient compared to specialization, but it paid off. When someone encountered a blocker, they could often resolve it themselves rather than waiting for the designated expert from another team. People preferred the variety. Nobody wanted to spend their career on a single narrow task.
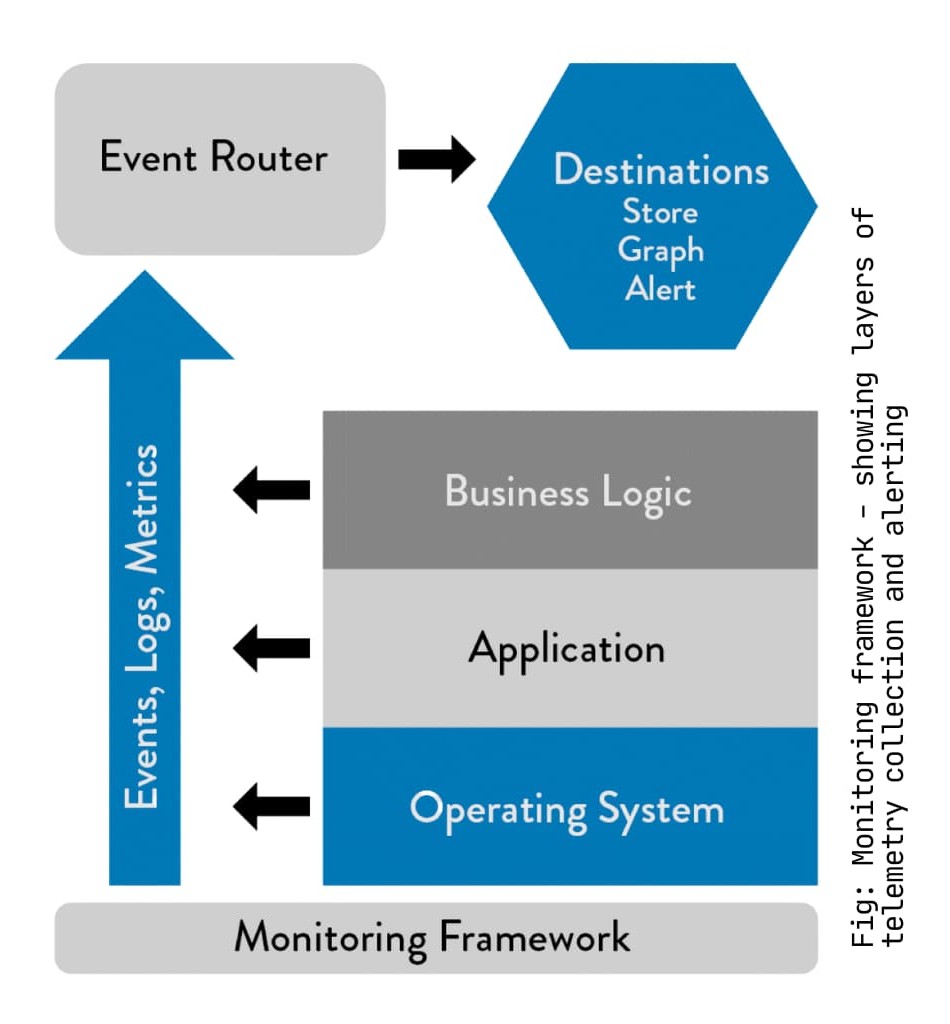
Telemetry: Instrumentation at Scale
Scott Prugh from CSG made an observation that stuck with me: “Every time NASA launches a rocket, it has millions of sensors. Yet we often don’t instrument software with the same rigor.” We decided to instrument our systems with the same discipline NASA applies to rockets.
We added telemetry at five levels:
- Business metrics: Sales transactions, user signups, churn rates, A/B test results.
- Application metrics: Response times, error rates, transaction volumes.
- Infrastructure metrics: CPU usage, disk usage, network traffic, database performance.
- Deployment metrics: Build status, deployment frequency, time from commit to production.
- Security metrics: Authentication failures, invalid inputs, circuit breaker trips.
We used StatsD because it let developers add metrics with one line of code. If adding telemetry takes more effort than that, people won’t do it.
The goal was detecting problems before customers noticed them. We set alerts based on statistical deviations from normal patterns, not arbitrary thresholds. If response times suddenly doubled but were still under our threshold, we wanted to know.
 The Four Metrics That Matter
The Four Metrics That Matter
We tracked dozens of metrics, but four told us if we were improving:
- Deployment frequency: How often we shipped to production.
- Lead time: Time from commit to production deployment.
- Mean time to repair (MTTR): Recovery speed from incidents.
- Change failure rate: Percentage of deployments requiring rollback or hotfix.
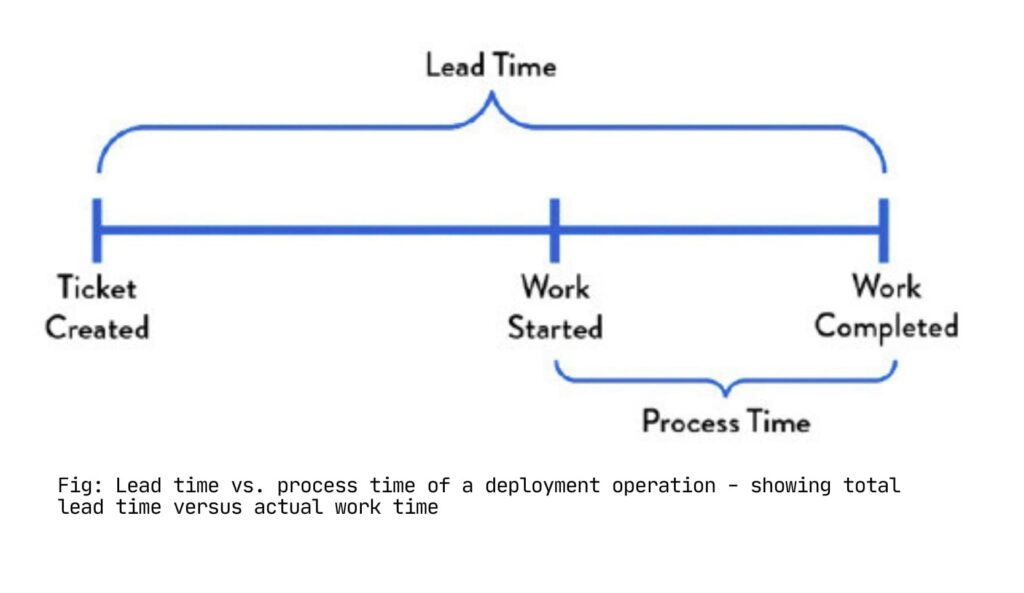 Everything else was secondary. These four metrics capture speed and stability. High-performing teams deploy frequently, with short lead times, low failure rates, and fast recovery when problems occur.
Everything else was secondary. These four metrics capture speed and stability. High-performing teams deploy frequently, with short lead times, low failure rates, and fast recovery when problems occur.
We also tracked one operational metric: the number of approvals and meetings required to deploy. Every approval was friction. Our goal was reducing that number to zero for standard changes.
Game Days: Practicing Failure Scenarios
Netflix runs Chaos Monkey, a tool that randomly terminates production servers. This seems reckless until you recognize that server failures are inevitable. The question is whether you want to develop recovery procedures during a controlled exercise or during a customer-facing incident.
We initiated Game Day exercises. We intentionally introduced failures in staging environments and practiced recovery procedures. The first few exercises were chaotic. By the fifth iteration, the team had documented runbooks, established communication protocols, and could restore service in minutes.
Resilience comes from practice, not from hoping nothing breaks.
What Changed at Noodle
We didn’t implement everything in the book. We focused on what solved our specific problems:
We adopted Scrum with actual work-in-progress limits. We reorganized into cross-functional teams around customer engagements. We built reusable frameworks for common tasks: data pipelines, ML model templates, deployment scripts, documentation. We standardized onboarding, CI/CD, and monitoring practices. We embedded RACI matrices and Kanban boards into daily work.
The quantitative results were measurable: 40% increase in code reusability, six-week reduction in production timelines. The qualitative shift was more significant. We stopped celebrating heroics and started building systems that functioned reliably without them.
What I’d Do Differently
Some things worked better than others. Trunk-based development took longer to adopt than I expected. Engineers were used to feature branches and needed time to adjust to working in smaller increments. I should have invested more in pairing and mentoring during that transition.
The Game Day exercises were hard to schedule. Production incidents always took priority, and people saw exercises as optional. I eventually started treating them like mandatory sprint rituals, which helped with consistency.
Telemetry was easier to add than to use effectively. We collected tons of metrics but didn’t initially have good dashboards or alerts. It took several months to tune the alerts so they caught real problems without creating alert fatigue.
Core Lessons
Three things stand out after implementing these practices:
1. Systems matter more than individual talent. A mediocre engineer in a good system will outperform a great engineer in a broken system. Most “performance problems” are actually systems problems.
2. Local optimization destroys global throughput. When each team optimizes for their own metrics, you create bottlenecks elsewhere. You need to optimize for the entire flow from idea to customer value.
3. Fast feedback beats perfection. Ship small changes quickly, measure the results, and adjust. This beats spending months building the “perfect” solution that might be solving the wrong problem.
The DevOps Handbook gave me the frameworks to diagnose what was broken at Noodle and the principles to fix it. But the real insight was simpler: you can’t scale a company on heroics. You need systems that work even when people are having an average day.
If you’re facing similar problems, start with visibility. Put up a Kanban board. Set WIP limits. See where work is actually getting stuck. You can’t fix what you can’t measure, and you can’t measure what you can’t see.
Good luck!