Choosing a market data vendor is one of those decisions that feels purely technical but quietly shapes everything that follows. For options products in particular, data isn’t just an input. It defines what you can test, what you can explain, and ultimately what you can trust.
While building the SmartOptions MVP, we spent a disproportionate amount of time evaluating options data vendors. That wasn’t accidental. Options data is uniquely complex, expensive, and sticky. Once you build on top of a vendor, switching later is rarely trivial.
This post walks through how we approached that decision, the trade-offs we made, and the lessons we learned, both technical and psychological, along the way.
The Hidden Cost of Vendor Lock-In and the Fear That Creates It
On paper, choosing a data vendor looks reversible. In practice, it rarely is.
Once a vendor is selected, teams begin accumulating sunk costs almost immediately: ingestion pipelines, data schemas, normalization logic, backtests calibrated to vendor-specific behavior, and assumptions baked into analytics and UI layers. Over time, these technical dependencies harden into something more subtle—cognitive commitment.
“We already understand this API.”
“Our backtests depend on this data.”
“Switching would mean re-validating everything.”
The real danger isn’t that switching vendors is impossible. It’s that teams quietly stop seriously considering switching long before they should. That early lock-in, often invisible at first, can shape product direction more than any explicit architectural decision.
This risk is amplified by a second force: the fear of starting over.
Data vendors are very good at selling future-proofing. Early in a product’s life, it’s tempting to optimize for a hypothetical future defined by millions of users, regulatory scrutiny, exchange-grade precision, and zero-latency execution. The anxiety is understandable: What if we choose wrong now and have to redo everything later?
But this fear frequently pushes teams to overbuy:
- Paying institutional prices for unproven ideas
- Integrating complexity they aren’t staffed to maintain
- Optimizing for scale before product–market fit exists
Starting over is costly—but starting wrong can be worse. The purpose of an MVP is not to eliminate future work; it’s to reduce uncertainty as quickly as possible. Recognizing both the sunk cost trap and the fear that fuels it was critical to how we approached our data vendor decision from day one.
Designing for Growth Without Overbuilding: Vendor Evaluation
Rather than trying to predict every future requirement, we focused on the directions in which our data needs were almost guaranteed to grow, and evaluated vendors against those axes from the start. The goal wasn’t to solve every future problem upfront; it was to avoid choices that would block us later.
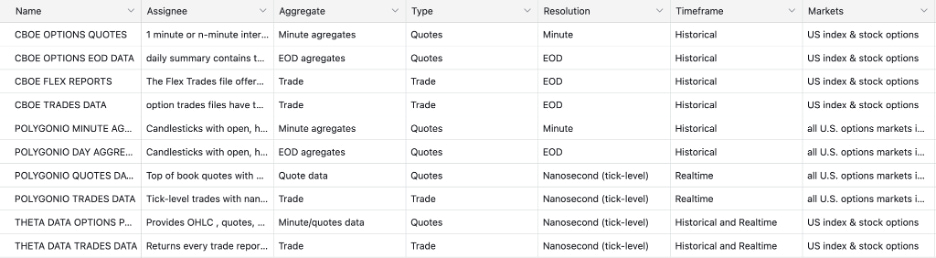
To do that, we grounded the decision in a clear set of vendor considerations shaped by three use cases: the MVP demo, historical backtesting, and an eventual live application. For options products, this immediately narrows the field.
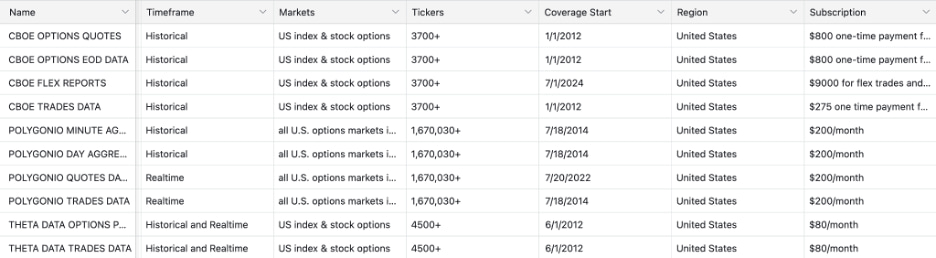
First, market coverage matters more than it initially appears. Options are not single instruments—they explode into chains of expirations and strikes. Any viable vendor needed to support at least five years of historical options data across liquid stocks, ETFs, and indices, with full historical contract coverage. Gaps here don’t show up immediately, but they surface painfully once strategies expand beyond a handful of names.
Second, granularity had to scale. Early validation works at end-of-day or minute-level resolution, but as strategies mature, questions quickly become more sensitive: spread dynamics, intra-minute price movement, and execution assumptions. We didn’t need tick-level data on day one but we didn’t want to discover later that it wasn’t available once the product demanded it.
Closely related was responsiveness and integration. Demos tolerate latency. Live systems do not. As products move closer to real users, predictable APIs, real-time streaming via WebSockets, and low-latency request handling become non-negotiable. Integration complexity isn’t just an engineering concern — it directly impacts how quickly you can iterate and how confidently you can operate.
Then there’s depth of fields, where options data truly separates itself from equities. OHLC prices alone are insufficient. A serious options platform needs bid/ask prices, open interest, implied volatility, and option Greeks. These fields aren’t “nice to have”—they define pricing accuracy, liquidity awareness, and risk interpretation.
Robustness was another key dimension. Vendors source data differently, and for options, aggregation matters. To reflect true market liquidity and realistic bid/ask spreads, data must be consolidated across major exchanges like NASDAQ, CBOE, and NYSE. Single-exchange or thinly aggregated feeds create silent inaccuracies that only emerge under stress.
Finally, pricing had to match the stage. Tiered models that separate historical from real-time access matter early. Institutional pricing can make sense at scale but it can also distort MVP decision-making if adopted too soon. Based on these criteria, this is how eight top option vendors compared:
Vendor Breakdown
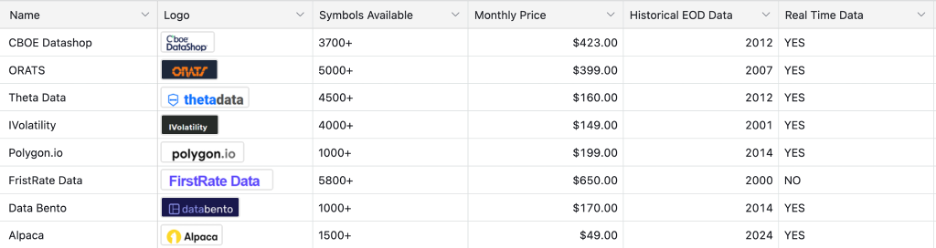
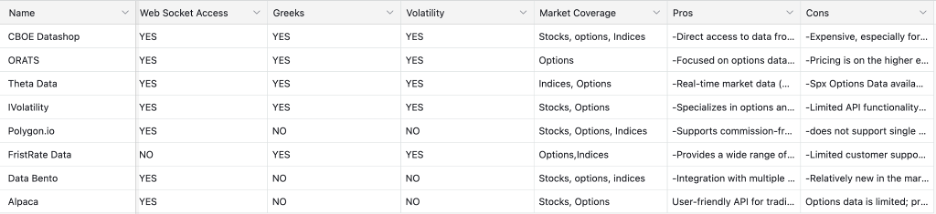
This analysis led us to a simple but grounding mental model: hold two vendors in mind at the same time. One represents what you need under MVP constraints—speed, affordability, flexibility, and learning velocity. The other represents what you’d choose with unlimited funding, millions of users, and institutional-grade requirements.
In an ideal world, you never have to start over. One vendor carries you from prototype to scale without friction. But acknowledging that a different vendor might make more sense down the road isn’t a failure of planning, it’s an honest reflection of how products evolve as constraints change.
We weren’t choosing one vendor forever. We were choosing one to learn with, and one to aspire to, while deliberately preserving the ability to move between them once the product earned that complexity.
Data Types: Where Vendor Differences Show Up
The biggest differences between options data vendors didn’t appear in pricing pages or feature lists—they emerged when we compared how different data types were packaged and delivered. To make that comparison meaningful, it’s essential to understand the distinctions between data types, since much of the confusion in vendor evaluations comes down to inconsistent terminology.
- Options Quotes are real-time, tick-level data containing bid/ask prices and sizes. This data defines what was tradable in the market and is the foundation for pricing, implied volatility, and liquidity analysis.
- Trades Data records executed trades at tick-level resolution. It’s essential for volume analytics, execution analysis, and flow detection, but insufficient on its own for continuous pricing.
- EOD Options Data provides daily aggregates—OHLC prices, volume, and open interest—for every listed contract. This data is primarily used for backtesting and historical modeling rather than live decision-making.
- Minute Aggregates roll option activity into fixed intraday intervals (e.g., 1-minute OHLCV). These are best suited for charting, intraday analysis, and strategy visualization.
- FLEX Reports are batch-delivered trade datasets, often customized and institution-focused. They’re useful for analyzing large, structured option trades and institutional flow, but not for real-time pricing or execution.
- Bulk historical data enables large-scale backtesting and research across time.
- Snapshots provide point-in-time views of the market, typically used for dashboards and UIs.
- Lists enumerate available option contracts and are critical for defining the historical universe and avoiding survivorship bias.
These data types aren’t interchangeable. Each answers a different question about the market, and meaningful vendor comparison requires understanding which fields appear in which data products, not just whether a vendor claims to “have the data.”
Different options data products serve very different purposes; the table below breaks down how each data type differs in timing, resolution, and ideal use case
| Data Type | Real-Time? | Granularity | Contains | Best for |
| Options Quotes | Yes | Tick | Bid/Ask, size | Pricing, IV, liquidity |
| EOD Options Data | No | Daily | OHLC, volume, OI | Backtesting, historical modeling |
| FLEX Reports | No (batch) | Trade | Custom institutional option trades | Institutional flow analysis |
| Trades Data | Yes | Tick | Executed trades | Volume analytics, execution, flow |
| Minute Aggregates | Yes | 1-min | OHLCV | Charting, intraday analysis |
These data types aren’t interchangeable—they answer different questions. Comparing vendors without understanding how fields are distributed across them obscures where real strengths and gaps actually lie.
Depth of Fields: Why ThetaData Won for the MVP
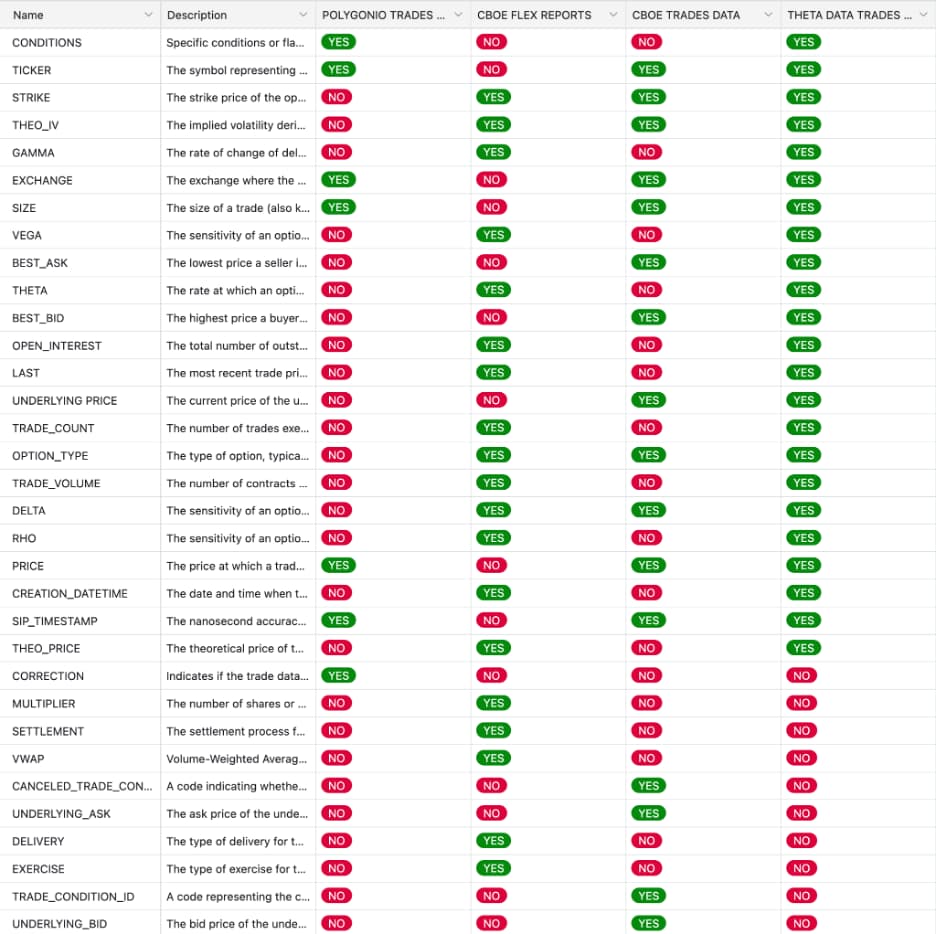
Once we aligned on data types, the next step was evaluating depth of fields; what information is actually available within each dataset. This is where meaningful vendor differences finally became visible. Rather than relying on feature lists, we compared vendors field by field and validated those comparisons by inspecting actual quote and trade data samples, not just documentation.
Looking at quote field coverage made the gaps obvious. Some vendors consistently exposed core option and underlying fields: underlying bid/ask, option bid/ask and sizes, Greeks, implied volatility, open interest, and volume. Others offered only partial context: prices without sizes, Greeks that required manual calculation, or trades without usable quotes.
This mattered because options data breaks down quickly without full context. Greeks, implied volatility, and even option prices become misleading if the underlying price or bid/ask is missing or misaligned. Quotes without sizes or open interest make it difficult to reason about liquidity or execution quality. Reviewing real data samples reinforced this; missing or inconsistent fields showed up immediately once you looked beyond schemas and into rows.
In these comparisons, CBOE Datashop had the most complete field coverage overall, particularly around underlying data and exchange-sourced quotes. ThetaData was a close second, covering nearly all of the fields required for pricing, risk, and liquidity analysis, with only minor gaps in non–option-specific underlying fields. Other platforms fell out of consideration simply because too many core fields were missing.
The deciding factor was price. CBOE’s per-ticker pricing, often hundreds of dollars per symbol, made broad experimentation impractical for an MVP. ThetaData delivered near-institutional depth, tick-level granularity, and broad historical coverage at a price that allowed us to explore widely and iterate quickly.
The takeaway was simple: depth of fields isn’t about how many columns exist; it’s about whether the right fields exist together and whether you can afford to use them at scale. Seeing those differences clearly, both in field comparisons and real data samples, made ThetaData the right choice for proving the concept without overcommitting too early.
Quote Field Comparison
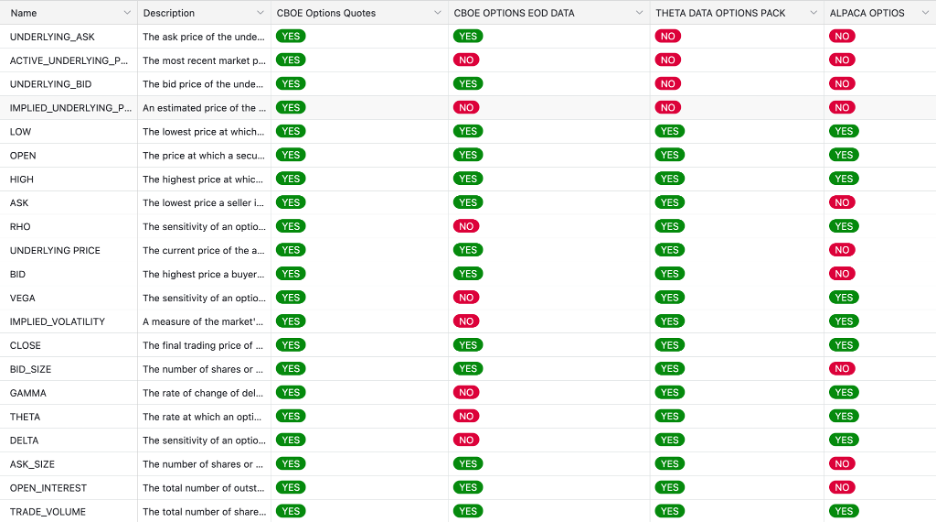
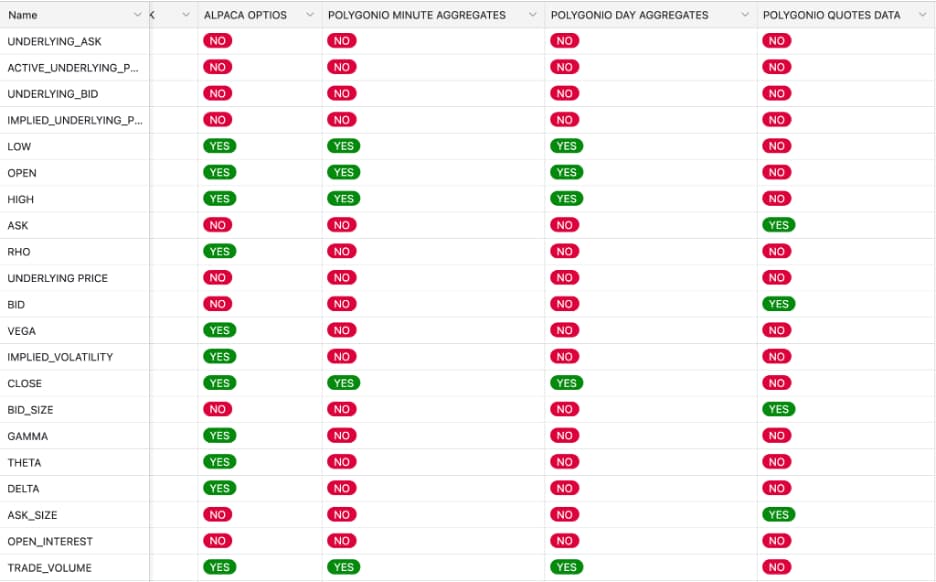
Trade Field Comparison
Vendor Data Samples
Building the ThetaData MVP Dataset
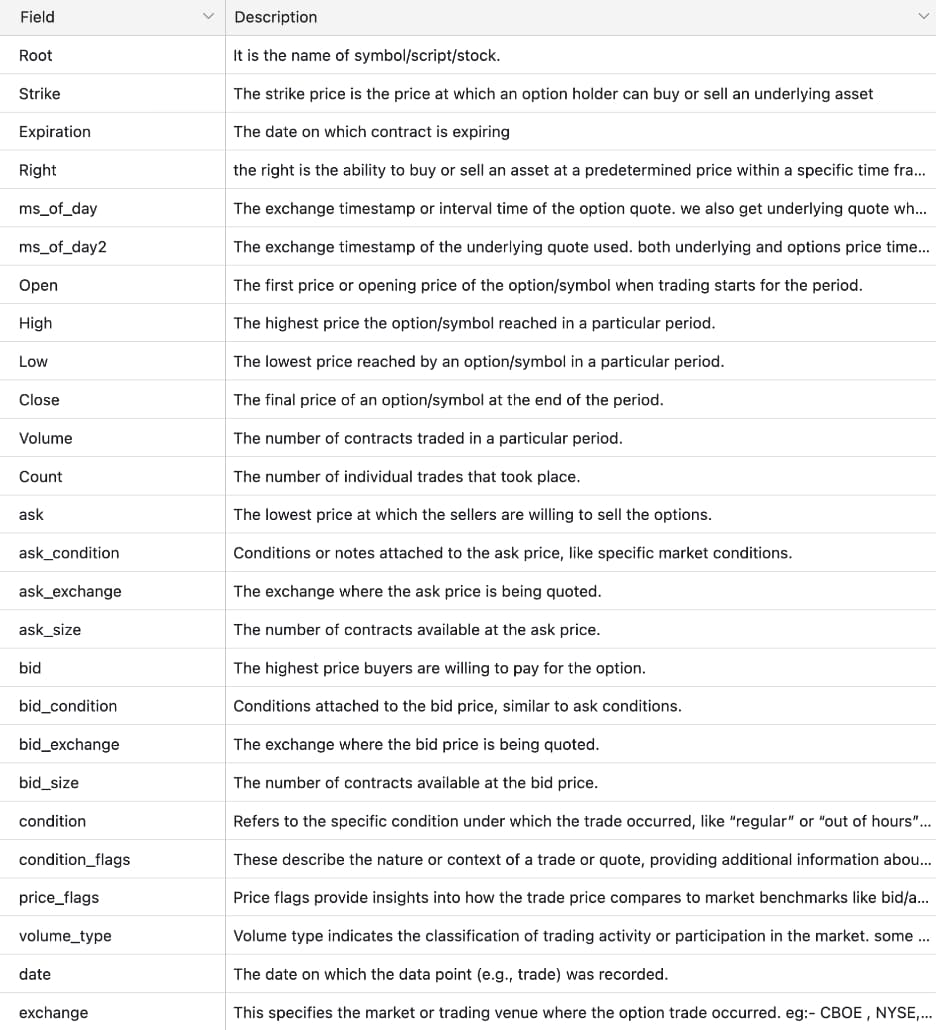
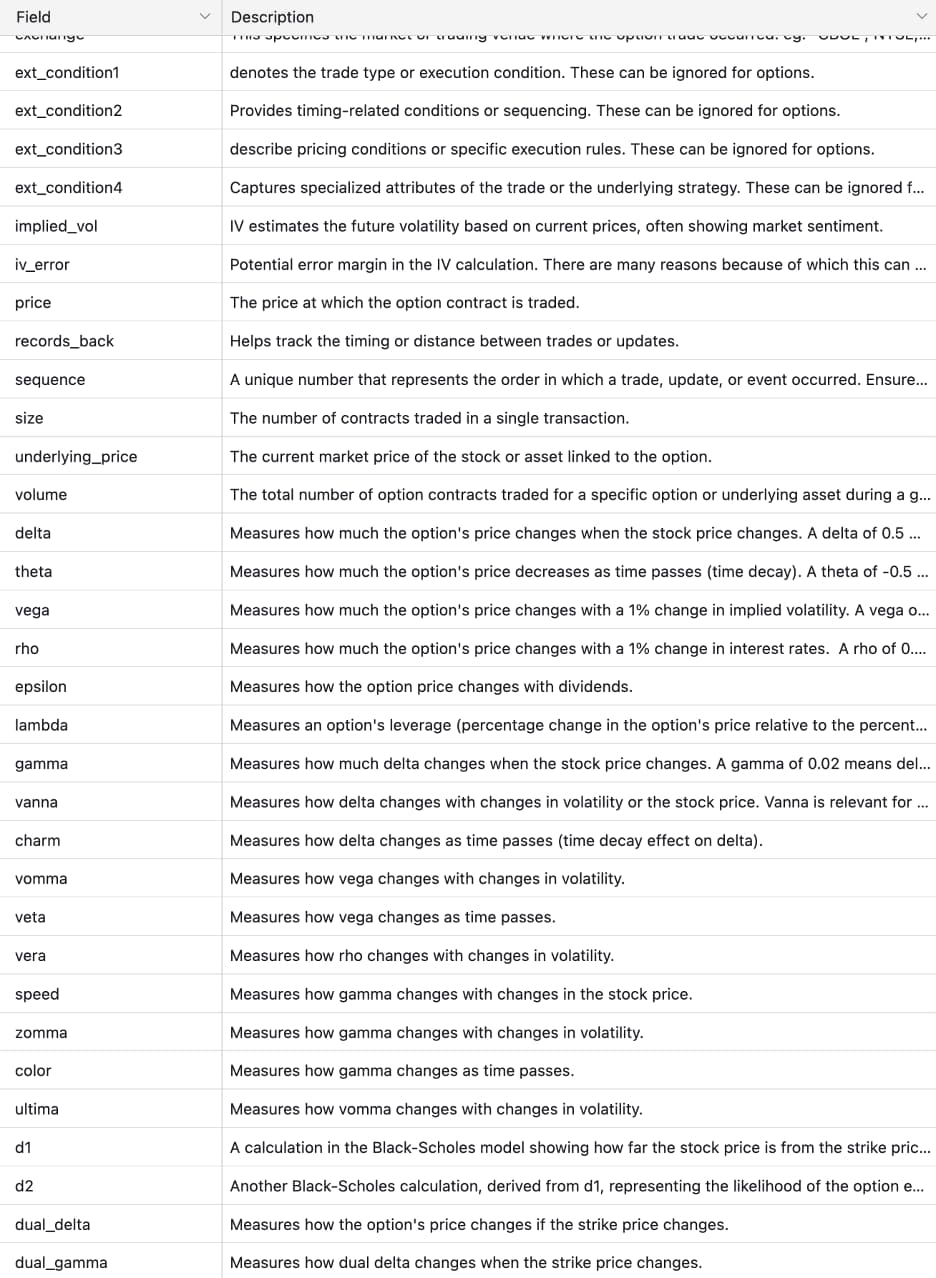
After selecting ThetaData, the next step was turning raw APIs into a dataset that could actually support the MVP. We started by reviewing ThetaData’s REST API surface and cataloging the unique fields exposed across endpoints, with a focus on what was required to reconstruct historical option positions accurately.
Rather than relying on a single feed, we combined three complementary APIs:
- Bulk Historical Greeks to track position status and risk over time
- Bulk OHLC to capture historical pricing
- Bulk Quotes to record bid/ask prices and sizes for liquidity and execution context
Together, these feeds allowed us to reconstruct option behavior at a granular level. ThetaData provides multiple historical resolutions—end-of-day, intraday (e.g., hourly, 30-minute, 1-minute), and full tick-level data with millisecond timestamps—as well as real-time streaming for live use.
By bulk downloading and merging these datasets, we were able to compute minute-by-minute P&L for individual option contracts across a defined historical window, while preserving full contract metadata such as strike, expiration, and option type. This approach gave us a realistic view of how positions evolved over time, without sacrificing performance or requiring institutional-grade infrastructure.
The result was an MVP dataset that balanced granularity, completeness, and practicality—accurate enough to validate pricing, risk, and liquidity assumptions, yet flexible and affordable enough to support rapid iteration.
ThetaData Rest APIs
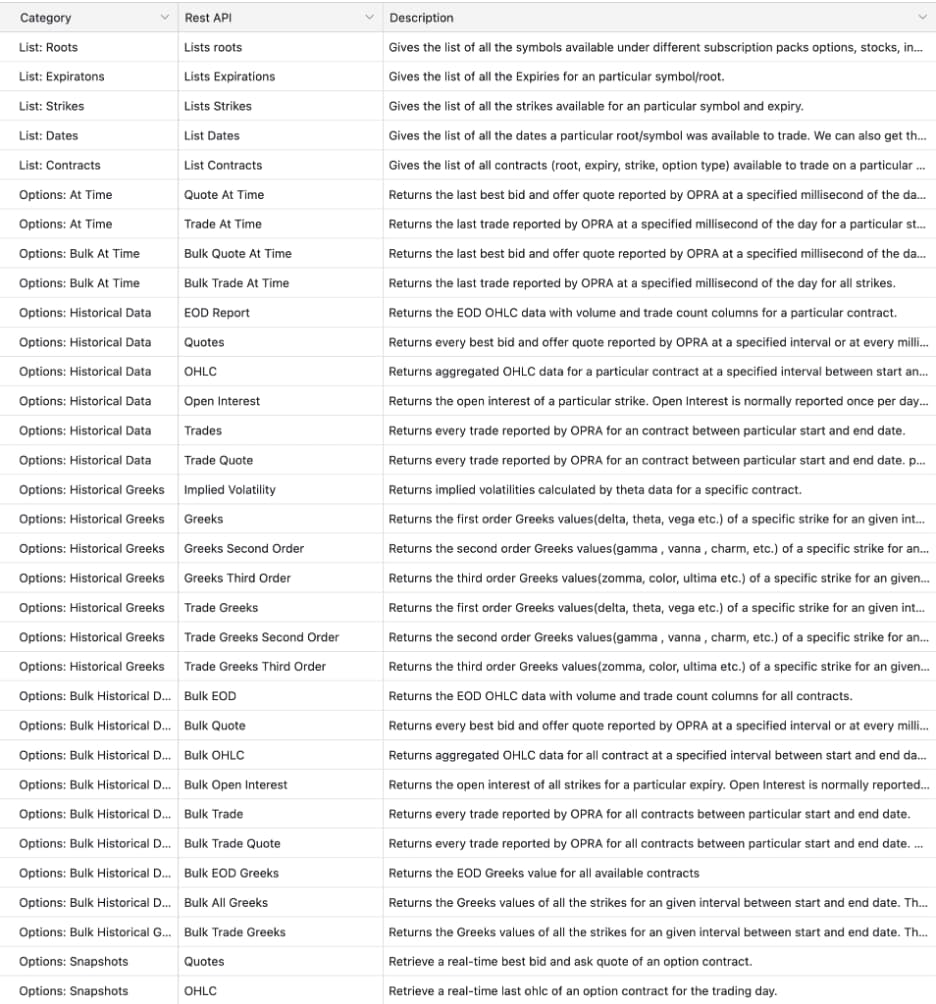

ThetaData Unique Fields
Nothing’s Ever Perfect — and That’s the Point
From a data-quality perspective, ThetaData checked nearly every box we needed for the MVP: broad options coverage, tick-level granularity, robust Greeks and implied volatility, and a price point that made wide experimentation possible. But no data vendor is without trade-offs.
ThetaData’s integration model introduces real friction. Accessing the data requires running a local terminal process that depends on Java and must stay online continuously, effectively acting as a proxy between your application and their servers. While this architecture enables high throughput, it also adds operational complexity; extra runtime dependencies, process management, terminal-specific errors, and more nuanced deployment considerations in cloud or containerized environments. Versioning differences between REST APIs and streaming support further raise the engineering bar.
These issues aren’t fatal, and they don’t negate the quality of the data. But they are real costs that teams need to account for in engineering time and operational overhead. Other vendors avoid some of this friction by offering direct HTTP and WebSocket APIs with simpler, cloud-native integration models.
The broader lesson is that nothing is ever perfect, especially at the MVP stage. The goal wasn’t to minimize long-term cost or pick a theoretically “best” provider. It was to maximize learning velocity: validate assumptions quickly, iterate broadly, strive for that one-fits-all solution while avoiding premature commitment to infrastructure we hadn’t yet earned.
That framing guided every decision. We optimized for flexibility over perfection, accepted the possibility of a future vendor switch, focused on the core fields and data types that actually matter, and treated integration complexity as a first-class concern rather than an afterthought.
Choosing an options data vendor isn’t about picking the strongest provider in absolute terms. It’s about choosing the one that lets you learn the fastest without quietly locking you into decisions too early. In the end, the most expensive data mistake isn’t paying too much. It’s realizing too late that you built on the wrong foundation.