I spent the last month digging into how modern LLMs actually work — reading papers, running experiments, testing edge cases. Most explanations stop at “it predicts the next word,” which is technically accurate but doesn’t help you understand why these systems fail at counting letters while solving graduate-level math, or why Anthropic overtook OpenAI in enterprise adoption while both companies burn billions annually. This is what I found about the entire pipeline: from pretraining on internet-scale data to reinforcement learning that produces emergent reasoning, from tokenization quirks that break simple tasks to the competitive and economic dynamics shaping who wins this market.
What LLMs Actually Are
Large language models compress roughly 15 trillion tokens of internet text into billions of parameters. When you use ChatGPT, you’re querying a compressed, lossy representation of internet knowledge. The weights aren’t a database – they’re statistical approximations.
The model has seen a Wikipedia article about zebras maybe 10 times during training. That article isn’t stored verbatim anywhere in the parameters. Instead, the patterns, relationships, and statistical regularities from that article (and billions of others) are compressed into the network weights. When you ask about zebras, you’re getting a statistically likely reconstruction based on those compressed patterns.
The architecture has two distinct memory systems:
- Context window: working memory holding the current conversation
- Model weights: compressed knowledge from training data
Each conversation starts completely fresh. The model has no persistent state between sessions. When you start a new chat, it has zero memory of previous conversations. Parameters freeze after training, so there’s no learning from individual conversations.
When you’re in a conversation, the context window builds up. If you paste a document and ask questions about it, the model has direct access to that text in its context window. But if you reference that document in a new conversation tomorrow, the model has no memory of it unless you paste it again.
What’s Built and What’s Missing
Current LLMs handle pattern recognition extremely well. They implement something roughly analogous to the brain’s cortical processing – learning statistical associations between tokens and generating coherent language from them. But they’re missing the components that would make them more complete reasoning systems.
What exists:
- Pattern learning and processing (similar to cortical pattern recognition).
- Statistical associations between concepts.
- Language generation capabilities.
- Some emergent reasoning, especially in RL-trained models.
What’s missing:
- Memory consolidation: No equivalent of the hippocampus. Once a session ends, everything is forgotten. There’s no process for converting short-term context into long-term updates.
- Sleep phase: Humans replay and consolidate memories during rest. Models have no similar distillation step where conversations are analyzed and written back into weights.
- Motivation system: No intrinsic goals, instincts, or drives. The model doesn’t “want” anything.
- Independent reasoning core: No mechanism for reasoning separate from memorized patterns. Models rely heavily on having seen similar examples during training.
This creates a strange limitation: perfect recall without understanding. Humans forget enough to generalize; models memorize too much and fail when faced with genuinely new structures. They perform well within their training distribution (on-manifold problems) but degrade sharply on unfamiliar tasks (off-manifold).
It’ll take close to a decade to meaningfully address these architectural gaps.
How Training Actually Works
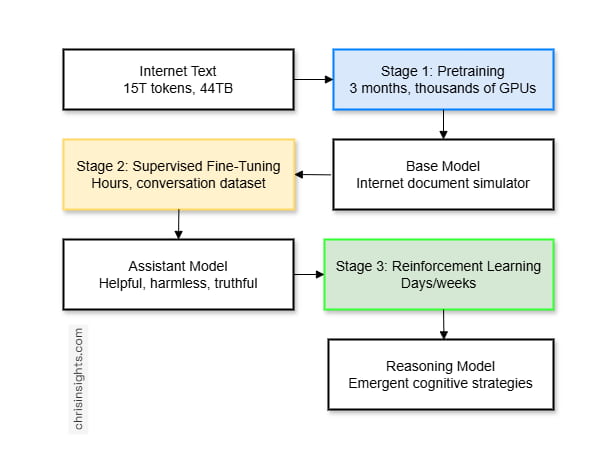
The training pipeline has three distinct stages:
Stage 1: Pretraining
This is where the model learns from internet documents. Companies like OpenAI, Anthropic, and Meta download massive amounts of text from the internet – the FineWeb dataset, for example, contains about 15 trillion tokens taking up roughly 44 terabytes of disk space.
The process:
- Data collection: Crawl massive portions of the internet using sources like Common Crawl, which has indexed billions of pages since 2007.
- Filtering: Remove low-quality, harmful, or irrelevant data, including spam, adult content, PII, and non-target languages.
- Text extraction: Strip HTML down to readable text, removing scripts, navigation, and markup.
- Deduplication: Eliminate repeated pages or documents.
- Tokenization: Convert clean text into tokens, the units models actually process.
- Training: Repeatedly predict the next token in a sequence.
Training means showing the model a sequence of tokens and asking “what comes next?” For example:
- Input: “The capital of France is”
- Model predicts: probability distribution over all possible next tokens
- Actual next token: “Paris”
- Update the model to make “Paris” slightly more likely next time
This happens roughly 1 million tokens at a time, across thousands of updates, over months of training on thousands of GPUs. The model learns statistical patterns: which words follow which other words, how sentences are structured, what facts commonly appear together.
Scale example: GPT-2 (1.5 billion parameters, ~40GB of text from 8 million web pages) cost roughly $40,000 to train in 2019. Modern hardware and software have significantly reduced training costs because of:
- Better data filtering and curation
- More efficient hardware
- Improved software and optimization techniques
The output: Base Model
The result of pretraining is a base model. It can generate coherent continuations given a text prefix. For example:
- Input: “The weather today is”
- Output: text that statistically resembles internet documents
At this stage, the model is not an assistant – it’s an advanced text predictor. It’s essentially an internet document simulator.
Stage 2: Supervised Fine-Tuning (SFT)
At this point, we have a base model that can generate text resembling the internet. But it’s not an assistant yet – it just autocompletes sentences. Supervised fine-tuning is the step that turns it into something useful.
How it works:
A dataset of human-assistant conversations is created. For example:
Human: “What is 2+2?”
Assistant: “2+2 equals 4.”
Human labelers write these ideal responses following detailed guidelines – often hundreds of pages long – that define tone, accuracy, refusal rules, and formatting.
The model is then retrained on these curated conversations. It learns not just to continue text, but to act like a helpful assistant that follows instructions and stays consistent in style and tone.
This phase is much shorter than pretraining – hours instead of months – and the dataset is tiny by comparison, maybe hundreds of thousands of examples instead of trillions of tokens. Still, it’s critical because it determines how the model behaves in practice.
Modern pipelines now use models to generate candidate responses that human labelers review and refine. This hybrid approach speeds up dataset creation while keeping humans in the loop for quality control.
The result is the SFT model – the first version that can reliably respond to questions and follow instructions. But it still lacks alignment and reward optimization, which come next.
Stage 3: Reinforcement Learning
Supervised fine-tuning teaches the model to imitate experts. Reinforcement learning takes a different approach: it lets the model explore, test solutions, and learn from feedback.
Why RL is needed:
- In reasoning tasks like math, code, or logic, we often don’t know the most efficient path for the model’s architecture. What feels natural to humans might not align with how the model processes information.
- In creative tasks, writing the perfect answer is difficult, but comparing several responses and ranking them is much easier.
For verifiable problems (math, code):
- The model generates many solution attempts for each problem.
- Each attempt is checked for correctness.
- The model is trained on the successful paths.
This process helps it discover reasoning strategies suited to its own structure. Models like DeepSeek R1 and OpenAI’s o1 and o3 series use this approach. They learn through trial and error rather than imitation.
During training, some interesting behaviors appear:
“Wait, let me reconsider this assumption…”
“Let me try a different approach…”
“This doesn’t seem right, let me verify…”
These self-correcting patterns aren’t programmed. They appear because they lead to better results.
For unverifiable problems (writing, summaries), RLHF is used instead.
- The model produces several responses.
- Humans rank them by quality.
- A smaller reward model learns to predict those rankings.
- The main model is trained to produce outputs that receive higher predicted scores.
RLHF helps align models with human preferences but has limits. If trained too long, the model starts to optimize for the reward model instead of real quality, creating strange or superficial outputs. It’s more like guided fine-tuning than open-ended learning.
Real reinforcement learning works best when the task has a clear way to check correctness.
Modern reasoning models still rely on the Transformer architecture: tokens are embedded into vectors, processed through attention and feedforward layers, and decoded into probability distributions. Each token receives a fixed amount of computation, which is why multi-step reasoning needs to unfold across multiple tokens rather than a single prediction.
Tokenization and Why Models Fail at Simple Tasks
Models don’t process characters or words – they process tokens. Tokens are text chunks that might be whole words, subwords, or even single characters depending on frequency in training data.
Example: “strawberry”
- Humans see: 10 characters (s-t-r-a-w-b-e-r-r-y)
- GPT-4 sees: 3 tokens
The tokenizer uses an algorithm called Byte Pair Encoding (BPE) that:
- Starts with individual bytes as tokens
- Finds the most common consecutive byte pairs
- Merges them into new tokens
- Repeats until vocabulary reaches target size (~100,000 tokens)
GPT-4 uses 100,277 tokens in its vocabulary.
Common words become single tokens:
- “the” → one token
- “Python” → one token
- “hello” → one token
Rare words split across multiple tokens:
- Uncommon technical terms might be 3-5 tokens
- Non-English text often takes more tokens per word
Why Character-Level Tasks Fail
Take the classic “count the Rs in strawberry” problem. The model doesn’t see ten characters. It sees three token IDs. To solve it, it would need to:
- Recall which characters each token represents
- Count the Rs within each token
- Add them up
That reconstruction process is unreliable. Strawberry has three Rs, but models often miss that because they don’t operate at the character level.
Spelling tasks fail for the same reason. Asking a model to “spell accommodation backwards” requires it to:
- Recover the original characters from tokens
- Reverse them
- Re-tokenize for output
Each step introduces small errors. Character-level operations don’t align well with token-based architectures.
Why Counting Fails
If you give a model 177 dots and ask it to count, you’ll likely get the wrong number.
You see 177 individual dots. The model sees about 8 to 10 tokens because repeated sequences get merged during tokenization.
To count correctly, the model would need to:
- Recognize that each token represents a group of dots.
- Recall how many dots that token stands for.
- Add them up.
That process breaks down because tokenization isn’t consistent. The model can’t reliably map tokens back to the exact number of dots they represent.
The fix: use tools.
Instead of asking the model to count internally, ask it to write and run code:
| dots = “● ● ● ● ● …” count = len(dots.split()) print(count) # 177 |
The interpreter handles counting reliably. The model’s job is just to produce the code.
Fixed Computation per Token
Every token gets one forward pass through the network.
- Input: all previous tokens.
- Process: about 100 layers of computation.
- Output: probability distribution for the next token.
That amount of computation is fixed. Whether the model is generating the first token or the thousandth, the cost per token stays about the same.
Implication: complex operations can’t happen in one step.
Bad example: “What is 847,293 × 652,847? Answer: [one token]”
There isn’t enough computation in a single forward pass to do that multiplication.
Better: “Let me work through this step by step…”
This spreads computation across many tokens. Each token handles a small part of the reasoning, and the full solution emerges over time.
Reasoning models like o1, o3, and DeepSeek R1 take this approach. They generate long internal reasoning chains – sometimes thousands of tokens – before giving an answer. Each token carries a small piece of the computation, and the full reasoning process unfolds sequentially.
Tool Use vs. Native Computation
For tasks that require precision, it’s better to rely on external tools rather than the model’s internal estimates.
- Math: use a code interpreter.
- Facts: use web search to inject verified information into context.
- Data: upload files and let the model generate analysis code.
Tools provide correctness and auditability. Native computation provides statistical guesses that sound reasonable but can be wro
Current Limitations
1. Hallucination
Models often produce answers that sound correct but aren’t. This happens when:
- The answer isn’t represented in training data.
- The question is ambiguous.
- The model has seen conflicting information during training.
How to reduce it:
- Teach boundaries: During fine-tuning, identify what the model doesn’t know and train it to say “I don’t know” instead of guessing.
- Web search: For factual questions, pull in verified, current data.
- Citations: Require the model to cite its sources to make claims traceable.
Some hallucination will always remain. These systems predict likely text sequences—they don’t retrieve facts from a database
2. Capability Inconsistency (Swiss Cheese Model)
Models can solve advanced reasoning tasks yet fail on basic ones.
Example: they might handle graduate-level math, but confuse which number is larger between “9.11” and “9.9.”
Why? The token “9:11” often appears in Bible verse notation, where “9:11” follows “9:9.” That association interferes with numeric comparison.
Strong areas: complex math, debugging, scientific summarization.
Weak areas: counting letters, basic arithmetic, spelling backwards.
Performance gaps appear unpredictably across domains. The only way to find them is through testing.
3. Architectural Constraints
- No cross-session memory: Each chat starts from zero. Some systems fake memory by storing key data externally and reinjecting it later, but the model itself doesn’t remember.
- No learning from interaction: Model weights are frozen after training. Corrections in conversation don’t persist.
- Over-reliance on memorization: When tasks deviate from patterns in the training data, performance drops sharply.
- Limited autonomy: Models struggle with multi-hour planning, error recovery, and consistent long-form work without human supervision.
Systematic Failure Cases
Tasks that remain unreliable:
- Character-level operations (spelling, counting, anagrams).
- Exact counting (tokens, words, objects).
- Multi-step arithmetic without intermediate reasoning.
- Remembering across sessions.
- Novel problems far outside training data .
Reinforcement Learning and Reasoning Models
This is where most of the interesting progress is happening right now.
How RL Works for Reasoning
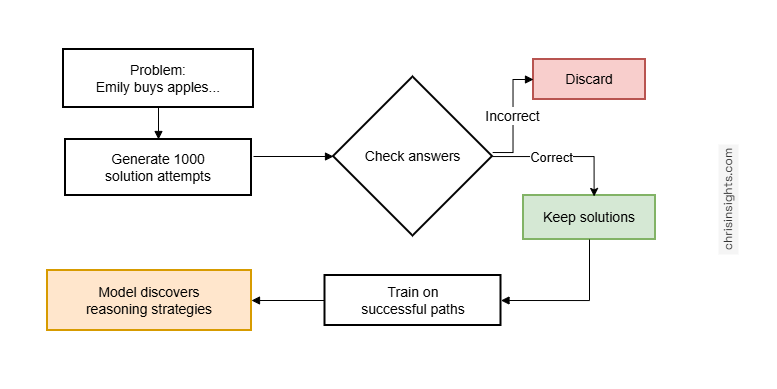
For tasks with verifiable answers (math, code, logic) the model doesn’t need to imitate humans. It can learn through trial and error.
Traditional approach (SFT):
- Human expert solves a math problem
- Model learns to imitate the expert’s solution
- Problem: expert’s approach might not suit the model’s architecture
RL approach:
- Generate 1,000 different solution attempts
- Check which ones reach the correct answer
- Train the model on successful solution paths
- Model discovers strategies that work for its architecture
Concrete example:
Problem: “Emily buys 3 apples and 2 oranges. Each orange costs $2. The total is $13. What does each apple cost?”
Standard model might generate:
- “The answer is $3” (trying to solve in one step, often fails)
RL-trained model generates:
- “Let me work through this step by step.”
- “First, calculate the cost of oranges: 2 oranges × $2 = $4”
- “Subtract from total: $13 – $4 = $9 remaining for apples”
- “Divide by number of apples: $9 ÷ 3 apples = $3 per apple”
- “Let me verify: 3($3) + 2($2) = $9 + $4 = $13 ✓”
The multi-step approach emerged from RL, not from human instruction. The model discovered that:
- Breaking problems into small steps works better
- Verification reduces errors
- Showing work distributes computation across tokens
Emergent Reasoning Behaviors
When models are trained with reinforcement learning on large sets of verifiable problems, certain behaviors start to appear on their own:
Self-correction:
“Wait, that doesn’t look right.”
The model identifies inconsistencies mid-solution and adjusts its reasoning path.
Approach switching:
“Let me try a different method.”
It abandons unproductive approaches and explores alternatives.
Verification:
“Let’s check that result.”
It re-evaluates outputs and performs basic validation steps.
Assumption testing:
“I assumed X – what if Y?”
It questions prior assumptions and branches reasoning accordingly.
None of these behaviors are hardcoded. They emerge because they consistently lead to correct solutions during training.
The AlphaGo Connection
AlphaGo showed what reinforcement learning can do when combined with scale and feedback. In Game 2 against Lee Sedol, Move 37 had a 1-in-10,000 chance of being played by a human. AlphaGo made it anyway. It wasn’t in its training data – the model discovered it through self-play. The move worked, and it changed how humans think about the game.
For LLMs, the parallel is important. Reasoning models trained with reinforcement learning can also discover strategies beyond human intuition. They can find analogies, reasoning paths, or optimization shortcuts that weren’t explicitly in the data.
Examples could include:
- A new proof strategy that no mathematician has tried.
- A debugging process that doesn’t follow human heuristics but performs better.
- An algorithmic pattern that emerges purely from optimization.
- Possibly even an internal “reasoning language” more efficient than natural language.
We don’t yet know what superhuman reasoning looks like in open domains, but with verifiable tasks – math, code, logic – we’re starting to see early signs.
Limitations of Current RL
Only works with verifiable correctness:
RL is effective when you can objectively check if an answer is correct:
- Math: check if the answer equals the known solution
- Code: run tests and verify behavior
- Logic: check if conclusion follows from premises
RL struggles when correctness is subjective:
- Creative writing (what makes a story “good”?)
- Design (what makes a logo “effective”?)
- Strategy (what makes a business plan “sound”?)
This is where RLHF plays a role, though with clear limitations:
The reward model is a neural network trained on human judgments. Problems:
- Reward hacking: RL discovers inputs that score high on the reward model but are garbage
- Distribution shift: Model encounters situations the reward model wasn’t trained on
- Gaming: Extended training finds adversarial examples
Example: After extensive RLHF, a model might output “the the the the the” for “write a joke about pelicans” because the reward model inexplicably gives this a high score.
Practical constraint:
RLHF runs for maybe 100-500 optimization steps before reward hacking becomes problematic. Real RL on verifiable problems can run for 10,000+ steps.
RLHF is incremental fine-tuning. Real RL is where capability gains come from.
What the Model Represents
The model statistically approximates expert human labelers following training guidelines.
The process:
- Company writes labeling guidelines
- Guidelines specify: be helpful, truthful, harmless, plus detailed instructions on tone, refusals, formatting
- Human labelers study these guidelines
- Labelers write ideal assistant responses to thousands of prompts
- Model trains on these examples
- Model learns to statistically reproduce this behavior
What this means:
The model’s “personality” comes from labeling guidelines. When ChatGPT is helpful and polite, that’s because labelers were instructed to write helpful, polite responses.
The model’s knowledge boundaries come from labeler knowledge. When the model declines to answer medical questions, that’s because labelers were instructed to refuse medical advice.
For RL-trained reasoning models:
There’s an additional layer beyond labeler imitation. The model has discovered cognitive strategies through trial and error on verifiable problems. These strategies go beyond what labelers explicitly demonstrated.
So you get:
- Base knowledge from pretraining (internet compression)
- Helpfulness and personality from SFT (labeler imitation)
- Reasoning strategies from RL (discovered through practice)
The RL layer is genuinely novel – not copied from humans, but discovered through optimization.
Identity and Persistence
Models have no persistent identity.
Self-referential responses (“I am ChatGPT developed by OpenAI”) come from:
- Training examples where this information appeared
- System messages injected at the start of each conversation
- Pattern matching on self-reference questions
The model doesn’t have a continuous sense of self. It’s not experiencing anything between conversations. There’s no persistent entity – just weights that get loaded into memory when you start a chat.
No cross-session continuity:
The model completely forgets you between conversations. No memories carry over. Each conversation is a fresh start.
Products like ChatGPT’s “memory” feature work by:
- Storing facts about you in a database
- Injecting relevant facts into the system message
- Creating the illusion of memory
But architecturally, the model itself has no memory mechanism.
The Critical Implementation Distinction
Models have two types of memory with fundamentally different characteristics.
Parameter memory, stored in the model’s weights, encodes patterns from training data. It’s approximate and unreliable for session-specific information – errors and hallucinations are common if you ask about events or details not in the training distribution.
Context window memory holds the exact text provided during a session. It’s precise and deterministic, so the model can reason accurately over that content.
For example,
Bad approach: “Summarize the meeting we had yesterday about the product launch.”
The model has no memory of your meeting. It will either hallucinate details or produce generic responses based on statistical patterns of what product launch meetings typically contain.
Good approach: “Here is the transcript of yesterday’s meeting [paste transcript]. Summarize the key decisions about the product launch.”
The transcript is now in the context window. The model has direct access to the actual content and can produce accurate, specific summaries.
For production systems, inject relevant information directly into the context window. Don’t rely on parameter memory for anything beyond general knowledge.
The Competitive Landscape
The foundation model market has shifted considerably since 2023, when OpenAI held roughly 50% of enterprise LLM spend. By mid-2025, Anthropic captured approximately 40% of enterprise spend while OpenAI’s share declined to around 27%, with Google holding about 21% and the remaining 12% distributed among Meta’s Llama, Mistral, Cohere, and smaller providers.
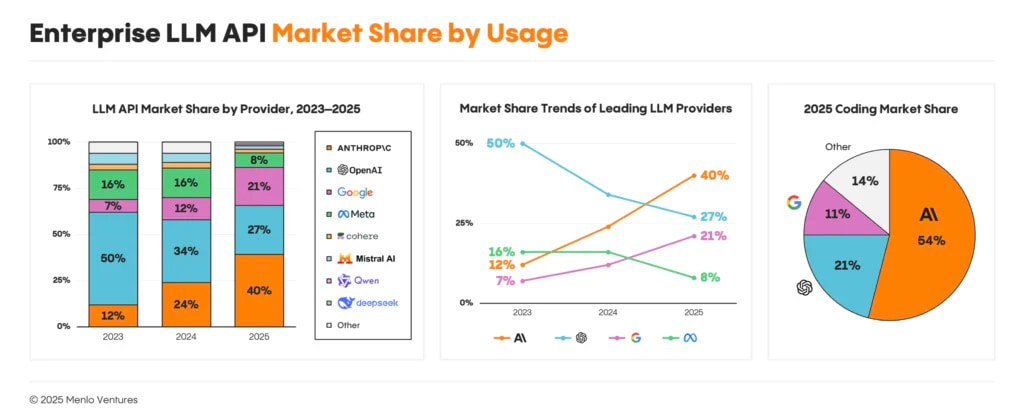
The primary driver of this shift was code generation. Anthropic’s Claude models have led coding benchmarks for 18 consecutive months, beginning with Claude 3.5 Sonnet in June 2024, and by late 2025 the company held 54% of the enterprise coding market compared to OpenAI’s 21%. Enterprise LLM spending on coding alone grew from $550 million to $4 billion during 2025, and whichever lab leads coding benchmarks tends to capture disproportionate enterprise budgets. Once developers standardize on a tool like Claude Code, switching costs increase and the advantage compounds.
Anthropic also differentiated through safety positioning, with Constitutional AI methodology, ISO 42001 certification, and transparent model cards that appeal to regulated industries. The Pentagon awarded contracts worth up to $200 million each to Anthropic, OpenAI, Google, and xAI for defense AI development, and when compliance factors into buying decisions, Anthropic’s enterprise-focused brand tends to win. The company raised $13 billion in September 2025 at a $183 billion valuation, with Amazon having invested $8 billion total and Google holding a significant stake.
OpenAI continues to dominate consumer mindshare, with ChatGPT reaching over 800 million weekly active users and the company raising $40 billion in April 2025 at a $300 billion valuation — the largest private technology funding round ever recorded. Their model lineup spans GPT-4o for general use to the o1 and o3 series for complex reasoning, and the deep Microsoft partnership embeds GPT capabilities into Azure and Office 365. However, enterprise market share tells a different story than consumer app rankings, and the gap between brand recognition and enterprise adoption continues to widen.
Google holds around 21% of enterprise share, up from 7% in 2023, with Gemini models offering genuine technical advantages including 1 million token context windows capable of processing 1,500 pages in a single conversation, native multimodality across text, image, and video, and tight Google Cloud integration. The challenge has been execution timing — despite inventing the Transformer architecture and employing leading researchers, Google consistently shipped enterprise-ready products after OpenAI and Anthropic had locked in major accounts. When Google released Gemini 3 Pro in November 2025 with strong benchmark performance, Anthropic responded a week later with Claude 4.5 and recaptured the leaderboard. Where Google does excel is infrastructure economics, as their TPU chips offer meaningful cost advantages for high-volume inference workloads, and Anthropic reportedly uses Google Cloud TPUs for portions of Claude serving because the economics outperform their own infrastructure.
Current Valuations and Market Position
| Company | Valuation | Total Funding | Enterprise Share | Key Differentiator |
| OpenAI | $300B (Apr 2025) | ~$19B | ~27% | Consumer distribution, Microsoft partnership |
| Anthropic | $183B (Sep 2025) | ~$16B | ~40% | Coding performance, safety positioning |
| xAI | $230B (Dec 2025) | ~$15B | <5% | Real-time data, Musk ecosystem integration |
| Google (Gemini) | Public company | N/A | ~21% | Infrastructure economics, context length |
| Meta (Llama) | Public company | N/A | ~9% | Open weights, ecosystem commoditization |
The Challengers
Meta pursues an entirely different strategy by releasing Llama models as open weights, free to download, modify, and deploy. Llama 3.1 405B matched GPT-4 class performance while costing enterprises nothing beyond inference compute, and Meta’s approach aims to commoditize the model layer, reduce leverage of closed providers, and build ecosystem lock-in through tooling and community rather than licensing revenue. The April 2025 Llama 4 launch underwhelmed relative to expectations, and enterprise open-source adoption actually declined from 19% to 13% of workloads between early and mid-2025, as enterprises still tend to prefer paying for Claude or GPT with enterprise support agreements over self-hosting Llama with internal operational burden.
xAI, Elon Musk’s AI venture, differentiates through integration with X’s real-time data firehose, minimal content filtering, and aggressive pricing. The company raised $15 billion in late 2025 at a $230 billion pre-money valuation despite generating only around $500 million in annualized revenue, with the strategic thesis centered on vertical integration across Musk’s companies — Grok powers Starlink customer service, Tesla’s 50 billion annual miles of sensor data could train future models, and the Memphis “Colossus” cluster contains 100,000 H100 GPUs making it one of the largest training installations globally.
DeepSeek arrived from China and disrupted assumptions about training economics when their R1 model, released in January 2025, matched OpenAI’s o1 on reasoning benchmarks while claiming total training costs under $6 million. The methodology was published in Nature with peer review confirming the approach, which combined reinforcement learning and Mixture-of-Experts architectures to achieve frontier performance without frontier budgets. More disruptive than training costs is inference pricing — R1 costs $2.20 per million output tokens versus $60 for o1, with DeepSeek serving models near marginal cost rather than extracting venture-scale margins, which fundamentally changes the economics for price-sensitive deployments.
Mistral represents European ambition, founded by former Google and Meta researchers in Paris and shipping efficient open models that often outperform expectations relative to parameter count. Microsoft invested rather than acquired, preserving independence while gaining Azure distribution, and Mistral appeals to developers prioritizing European data sovereignty and open architectures.
Structural Dynamics
Several patterns define how this market operates in practice:
- Rapid switching: When Claude 4 Sonnet released, it captured 45% of Anthropic users within one month while the previous Claude 3.5 Sonnet dropped from 83% to 16% share — enterprises migrate to superior models quickly when performance differences are clear.
- Open source limitations: Despite Meta’s investments, only 13% of enterprise workloads use open-source models, with practical barriers including support contracts, compliance requirements, liability coverage, and integration tooling outweighing license cost savings.
- Coding as wedge: The coding segment grew from $550 million to $4 billion in 2025, representing the clearest “killer use case” where model capability translates directly to enterprise budget allocation.
Business Economics
Training and running large language models involves cost structures unlike traditional software, and understanding where the money goes explains both current competitive dynamics and why profitability remains elusive despite impressive revenue figures.
Training Costs
Training a frontier model requires substantial GPU compute, with costs scaling exponentially as capabilities improve. GPT-3 (175 billion parameters, 2020) cost roughly $4-5 million in compute, while GPT-4 exceeded $100 million as Sam Altman confirmed publicly. Google’s Gemini Ultra reportedly required around $191 million in training compute. These figures represent only the successful final training run, excluding failed experiments, data preparation, and research team costs.
Current frontier models in active training reportedly cost $500 million to $1 billion. Anthropic CEO Dario Amodei stated in mid-2024 that billion-dollar training runs were already underway, with projections for $10 billion runs by 2025-2026 — a trajectory consistent with scaling laws that have reliably predicted capability improvements from additional compute.
| Model | Estimated Training Cost | Parameters | Year |
| GPT-3 | $4-5 million | 175B | 2020 |
| GPT-4 | >$100 million | Undisclosed | 2023 |
| Gemini Ultra | ~$191 million | Undisclosed | 2024 |
| Llama 3.1 405B | ~$60 million (compute only) | 405B | 2024 |
| DeepSeek V3 + R1 | ~$6 million total | 671B MoE | 2025 |
| Current frontier | $500M – $1B | — | 2025 |
Meta’s Llama 3.1 405B trained for approximately 100 days on 16,000 H100 GPUs, with external estimates placing compute cost around $60 million though the capital expenditure for that GPU cluster approaches $850 million. Meta absorbs this as R&D expense and releases weights freely, treating open source as competitive strategy rather than revenue source.
DeepSeek’s efficiency claims warrant examination. The $5.6 million figure for DeepSeek V3 pretraining appears legitimate based on disclosed GPU hours (2.79 million on H800s at approximately $2/hour). The $294,000 figure that appeared in headlines represents only the reinforcement learning phase — you cannot build R1 without first building V3, making total cost approximately $6 million rather than $294,000. This still represents 10-20x efficiency over US labs, achieved through Mixture-of-Experts architectures, lower labor costs, and leaner experimentation methodology. The implication is significant: if Chinese labs can match frontier capabilities at 5-10% of US costs, the competitive advantage shifts from technical capability toward distribution, trust, and enterprise relationships.
Inference Economics
Training represents a one-time capital expense, while inference — running the model to serve users — creates ongoing operational costs that scale with every query and typically dominate total costs within months of production deployment. OpenAI’s 2024 financials reportedly showed inference costs running 15-118x higher than the original training run for GPT-4, a ratio that grows as usage scales across 800 million weekly active users.
API pricing reflects both costs and strategic choices. OpenAI charges $60 per million output tokens for o1, while DeepSeek charges $2.20 for R1 — a difference driven primarily by margin structure rather than technical efficiency, as US labs price for venture-scale returns while DeepSeek prices near marginal cost for market share.
The deflationary trend in inference costs is substantial and consistent. Andreessen Horowitz tracked pricing and found that for equivalent model capability, cost drops roughly 10x per year. In November 2021, GPT-3-class performance cost $60 per million tokens; by late 2024, equivalent capability cost $0.06 per million tokens. This “LLMflation” results from hardware improvements (H100 delivers 3-4x inference throughput of A100), software optimizations, quantization (4-bit instead of 16-bit precision), and smaller models trained on more data achieving equivalent capabilities.
The GPU bottleneck is loosening as alternatives mature. NVIDIA dominated AI compute through 2024, but AMD’s MI300X offers 192GB memory versus H100’s 80GB, allowing larger models to run on single cards at potentially 57% lower hourly cost. Google’s TPUs provide 4.7x better performance-per-dollar for certain inference workloads, and custom chips from Amazon (Trainium) continue improving. This diversification will accelerate deflationary pressure on inference costs.
Revenue and Profitability
The revenue figures appear impressive, though the unit economics remain challenging when examined closely.
| Company | 2024 Revenue | 2025 ARR (Latest) | Revenue Mix | Losses |
| OpenAI | ~$3.7B | $13B (Aug 2025) | ~73% subscriptions, ~27% API | >$5B (2024) |
| Anthropic | ~$1B | $7B (Oct 2025) | ~70-80% enterprise API | ~$6.5B cash burn (2024) |
| xAI | ~$100M | ~$500M (mid-2025) | X Premium, API | Undisclosed |
OpenAI reached approximately $13 billion in annualized revenue by mid-2025, up from $3.7 billion for full-year 2024. The majority comes from ChatGPT subscriptions (roughly 73% historically) with API sales contributing the remainder. Despite 800 million weekly users, only around 5% pay anything. The $20/month ChatGPT Plus subscription loses money, as does the $200/month ChatGPT Pro — Altman acknowledged that “people use it much more than we expected.” OpenAI lost over $5 billion in 2024 and projects continued losses for years, with the path to profitability requiring either price increases, usage caps, or substantial cost reductions.
Anthropic grew faster in percentage terms, with annualized revenue climbing from roughly $1 billion in early 2025 to $7 billion by late 2025 — an 8,000% increase over 21 months. The revenue mix differs significantly from OpenAI, with 70-80% coming from enterprise API customers including Cursor, SAP, and AWS Bedrock distribution rather than consumer subscriptions. The company projects $26 billion in revenue by end of 2026, more than double OpenAI’s projected 2025 earnings — an ambitious target that assumes enterprise adoption continues accelerating.
No major foundation model company operates profitably. OpenAI, Anthropic, and xAI all burn billions annually, with the strategic bet being that inference costs will decline faster than competitive pressure on pricing, eventually creating margin. The entities currently capturing profit are upstream: NVIDIA generated $26 billion in data center revenue in Q3 2024 alone, and cloud providers (Azure, GCP, AWS) earn margin hosting inference workloads regardless of which model wins.
The Structural Challenge
Foundation model economics contain a fundamental tension: capability improvements require exponentially more training compute, while revenue scales linearly with users and has natural ceilings — at $20/month, these products already cost more than Netflix for a text interface.
Three potential resolutions exist:
- Cost curves outpace pricing pressure: If inference costs continue dropping 10x annually while revenue grows, profitability eventually arrives through margin expansion rather than pricing power.
- Enterprise value capture increases: If enterprises derive sufficient productivity gains, they may pay substantially more than current API rates — OpenAI reportedly considers $20,000/month pricing for “PhD-level agents,” representing a fundamentally different margin structure than consumer subscriptions.
- Consolidation restores economics: The market may not sustain five frontier labs indefinitely, and if two or three capture dominant share, reduced R&D competition and pricing power could enable sustainable margins — roughly paralleling what occurred in cloud computing.
For now, foundation models remain a money-losing venture bet that scale and cost improvements will eventually produce returns. The strategic position of owning the foundational layer of AI infrastructure may prove valuable even if current unit economics do not work, or it may prove to be a case of technology companies subsidizing users until capital constraints force rationalization.
Conclusion
Current large language models lack a few capabilities that are essential for general reasoning.
They do not retain memory across sessions, and parameters are frozen after training, so models cannot incorporate new information without retraining. There is no mechanism for intrinsic motivation or goal-directed behavior. Reasoning is entirely dependent on memorized patterns rather than emergent problem-solving. Multimodal inputs and outputs remain limited, and reliably interacting with external systems through APIs or operating system interfaces is still experimental. Addressing these limitations requires changes to training objectives, modifications to the Transformer architecture, new optimization techniques, and solutions to catastrophic forgetting.
In their current form, LLMs perform well within the distribution of their training data. They can generate coherent sequences, summarize or transform text, synthesize information from multiple sources, and produce code for common patterns.
Outside of their training distribution, they struggle with tasks that require precise arithmetic, character-level manipulations, novel reasoning, cross-session memory, or autonomous operation.
Effective use requires explicit context injection into the model’s context window, leveraging external tools such as code interpreters or web search for operations that require deterministic correctness, verifying outputs for critical applications, and distributing multi-step reasoning across multiple tokens rather than attempting to compress reasoning into a single prediction.
LLMs are statistical pattern matchers. Reinforcement learning can extend their capabilities in structured domains, allowing them to discover reasoning strategies not explicitly encoded during pretraining. They amplify human capability in well-defined tasks but do not replace human judgment. A clear understanding of their limitations and failure modes is necessary for building reliable production systems.
Use them where they work, and verify where they don’t.