How We Improved Our API Integration Process
API integration can either be a massive engineering burden—or a compounding competitive advantage. At Plotter, we’ve gone through painful cases like BEA, BLS, and Econoday, and used those lessons to build tooling that makes every subsequent integration easier. Today, integrations that once took 30 days now takes 3 days.
Here’s how.
Feed Integration Strategy — Focus vs. De-Focus
This is the strategic layer behind everything we built.
The guiding rule: Simplify to scale. Differentiate to win.
Focus on structure, automation, and uniqueness, not blind expansion.
Every improvement in uniformity compounds across all future integrations.
✅ FOCUS ON — High-ROI Levers
Schema Normalization & Uniformity:
Standardizing formats and metadata boosts both quality and integration speed across all sources.
Integration Automation & Templates
Reusable SDKs, ETL scaffolds, and code templates cut complexity and accelerate onboarding.
Distinctive “Dual-Benefit” Feeds
Prioritize sources that combine broad coverage with unique insights.
Complexity Reduction via Tooling
Automate validation, ingestion, metadata extraction, and cross-referencing; each improvement scales portfolio-wide.
Scalability Optimization
Use async and batch ingestion to minimize rate-limit friction and maximize throughput.
Selective Premium Investment
Pay for proprietary feeds when they meaningfully differentiate the product—even if the data is costly.
Performance Sequencing
Normalize → Automate → Differentiate. This creates a compounding efficiency flywheel.
🚫 DON’T FOCUS ON — Low-Return Areas
Authentication Tuning
Most APIs already use simple API keys; optimizing further has negligible impact.
Expanding Data Availability Blindly
More feeds ≠ more value; quality and strategic fit matter more than quantity.
Feed Quantity Growth
Avoid redundant or low-impact sources that increase maintenance without improving user value.
Over-Optimizing Cost
Excessive cost-cutting usually harms data quality; balance affordability with differentiation.
Dataset Size Management
Storage is cheap—focus on throughput and structure instead.
Connectivity Modernization
REST/JSON is already universal; changes here yield marginal returns.
API Process Improvements
After identifying the strategic levers that matter most, we rebuilt our API integration workflow around reuse, standardization, automation, and scalable architecture.
1. Reuse Code, Tools, Processes — and Standardize Everything
The biggest efficiency gain came from building components we can reuse across sources: shared schemas, authentication modules, pagination handlers, metadata loaders, and transformation logic.
Lukasz, our backend engineer, summarized it perfectly:
“The more sources I load, the easier it gets. Tools from one API become templates for the next.”
Practical Reuse Examples
-
Metadata loading—once manual—is now automated.
-
Postman provides fast, consistent endpoint testing.
-
pgAdmin/PostgreSQL let us validate results and debug schemas.
-
Shared modules handle authentication, retries, pagination, compression, and format conversion.
Standardization is the Force Multiplier
We standardize every API into a unified schema so downstream systems don’t care whether data came from Alpaca, BEA, BLS, FRED, or Econoday.
Reusable modules now include:
-
Authentication
-
Retry & backoff
-
Pagination & batching
-
Format converters
-
Metadata extractors
-
Parallel ingestion pipelines
Each new source enhances the shared toolkit, making every subsequent integration faster.
2. Reuse Logic and Best Practices
Even though APIs differ dramatically—JSON vs XML, REST vs SOAP, clean schemas vs deeply nested structures—the engineering principles behind them stay consistent.
Lukasz describes it like this:
“Each source is a different puzzle, but the underlying skills are the same. Like an engineer building bridges. The size and materials differ, but the fundamental logic stays the same”
Reusable logic includes:
-
Authentication flows
-
Incremental update detection
-
Metadata cross-referencing
-
Error-handling patterns
-
Schema normalization
These patterns make integrations repeatable instead of bespoke.
3. Key Skills That Unlock Speed
To manage worst-case APIs like BEA, BLS, and Econoday, we invested in foundational engineering practices and applied them consistently.
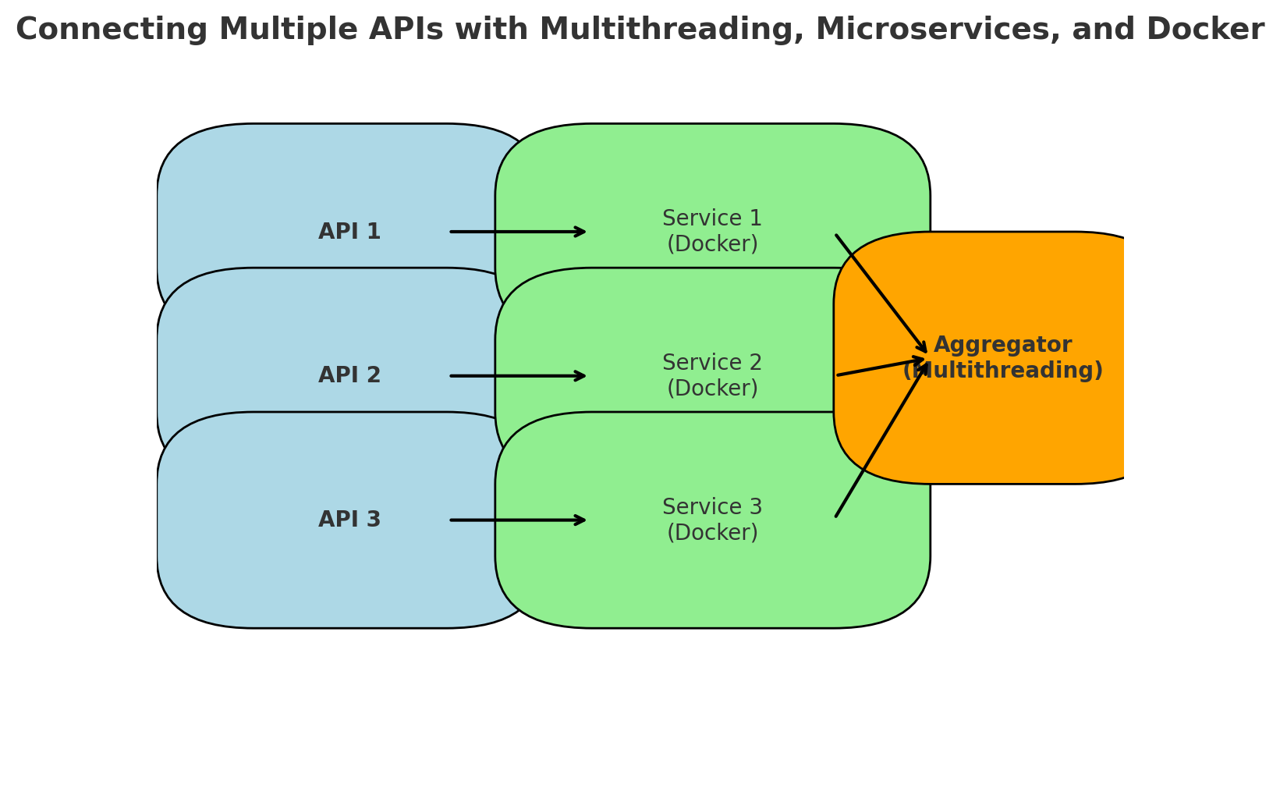 Multithreading / Async Processing
Multithreading / Async Processing
Lets you call multiple APIs simultaneously instead of sequentially. This speeds up data aggregation and reduces waiting time, especially when APIs are slow or rate-limited.
Microservices Architecture
Breaks integrations into separate small services – one per API. This keeps failures isolated. If one API crashes, it doesn’t take down everything else. Each service can scale, update, or be secured independently.
Docker Images
Package each integration with its own setup, libraries, and dependencies. This ensures the API connection works identically on your laptop, in testing, and in production. It makes deploying, updating, or rolling back individual connectors easier.
The first build is hard. By the tenth, you’re reusing most of the work.
4. Automation and Efficient Scaling
Wherever possible, we automated discovery, metadata extraction, validation, and updating.
Using those key skills described in step 3, each API runs inside a Dockerized microservice that:
-
Isolates failures
-
Scales independently
-
Updates safely
-
Rolls back instantly
Async and multithreaded ingestion allow us to saturate throughput without hitting rate limits.
High-volume sources like FRED—hundreds of series daily—benefit from batching and scheduling.
5. The Result
Integrations that used to take 30 days now take 3—not because engineers type faster, but because our infrastructure does the heavy lifting.
Users get instant access to 50+ data sources without worrying about:
-
Authentication
-
Pagination
-
File formats
-
Rate limits
-
Schema differences
- Metadata joins
-
Cross-referencing logic
They focus on insights—not ingestion. Users simply query clean, unified data.
That’s the difference between tools that are useful and tools that are essential.
Why This Matters
If your product relies on external data, API integration will either become:
• A strategic differentiator, or
• A perpetual engineering drag
The difference depends on whether you build one-off connectors—or reusable infrastructure.
We learned this the hard way with BEA, BLS, and Econoday.
Those integrations were painful—but they forced us to build tooling that now makes best-case APIs trivial.
The insight is simple:
API quality varies wildly, but if your system handles the worst cases gracefully, everything else becomes easy.
That’s what Plotter does. It’s not magic—it’s the result of hard-won lessons turned into scalable, reusable architecture.
Final Thought
We didn’t get faster by working harder. We got faster by building systematic infrastructure that compounds with each new integration.
That’s why Plotter can integrate 50+ data sources, maintain them reliably, and expose them through a single unified interface—while most teams struggle with just one or two.
If you’re building a data product, this is your roadmap:
Normalize → Automate → Differentiate
Everything else falls into place.